
git工作流
团队协作开发从来不是一件易事,要想让开发、发布、迭代的整个流程井井有条,我们需要思考的问题很多:
- 如何保证所有开发者写出的代码是美观且一致的?
- 如何防止可能存在问题的代码被提交到仓库?
- 如何借助工具来约束协作流程,使用规定代替约定,降低开发者的心智负担?
对于一个前端开发者而言,开发过程中的工作流大致如下图所示:
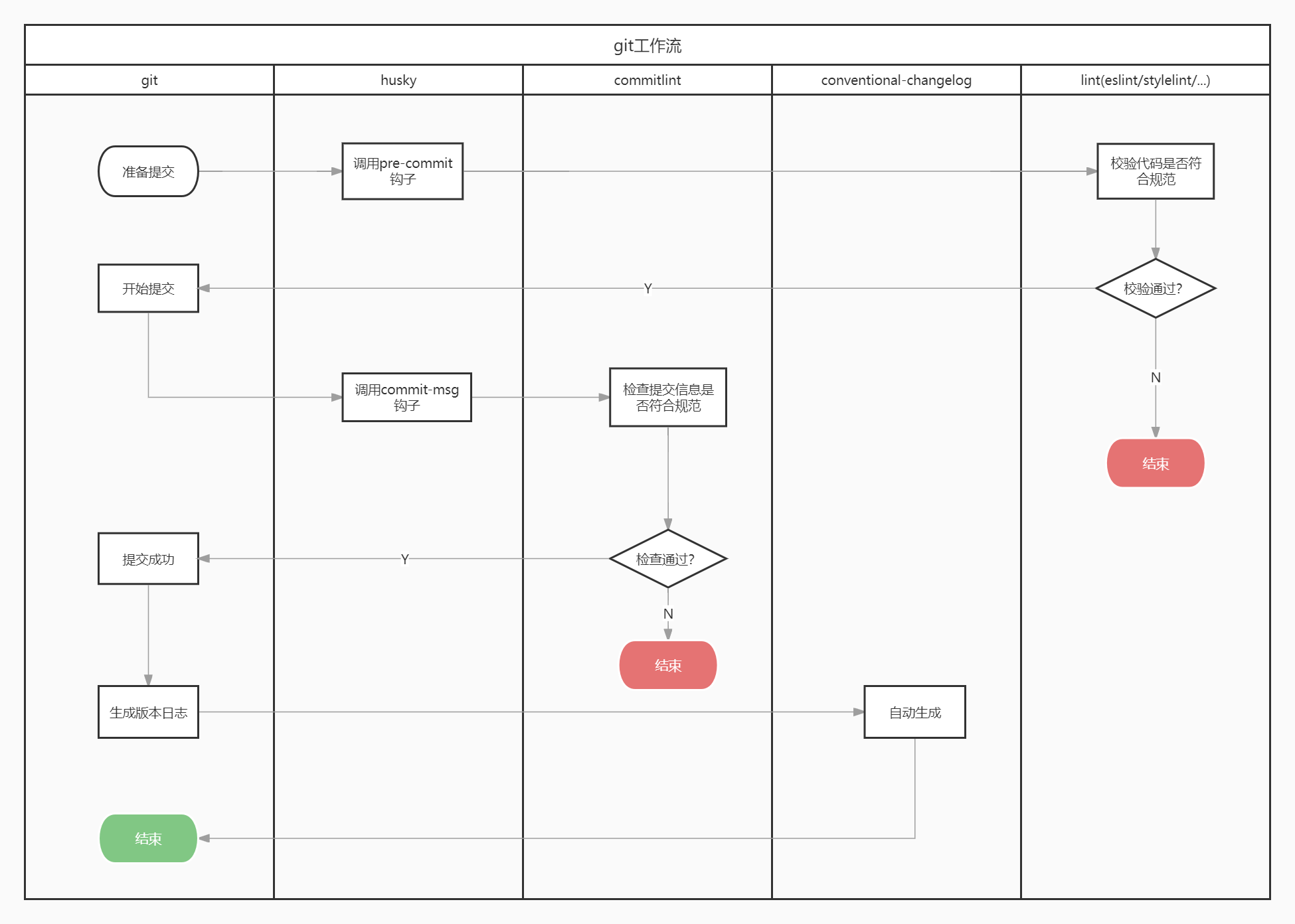
流程中的关键节点都有对应的第三方库来为我们快速地解决问题,组合使用这些库,我们可以搭建出一个非常标准化的git工作流。接下来我将详细描述整个标准化流程的搭建过程。
注意
以下流程的搭建只是一个最小版的最佳实践,读者朋友在阅读时,需要从原理出发去理解问题,切不可按照文中的流程机械性地复刻操作,这样是不得灵魂的。
每个章节都有高级的实践方法,后续我会补充一个高级实践篇,讲述特定场景下的高级用法。
husky入门
下载并初始化
首先,确保目录下存在package.json文件,并且该目录为一个git仓库。
然后,执行以下命令,初始化husky,并安装依赖。
npx husky-init && npm install # npm
npx husky-init && yarn # Yarn 1
yarn dlx husky-init --yarn2 && yarn # Yarn 2+
pnpm dlx husky-init && pnpm install # pnpm初始化完成后,目录下会生成.husky目录:
|── .husky
|── _
|── .gitignore
|── husky.sh
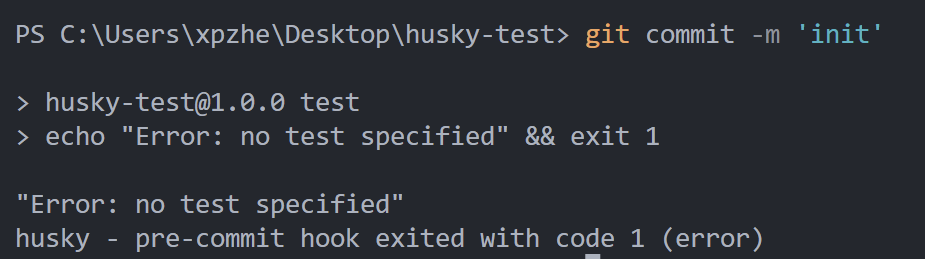
|── pre-commit其中,pre-commit是husky自动创建的提交前钩子,其内容为:
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm test当提交代码时将会执行npm test命令(由于该命令默认会打印一句话并退出,所以提交会发生错误而失败):
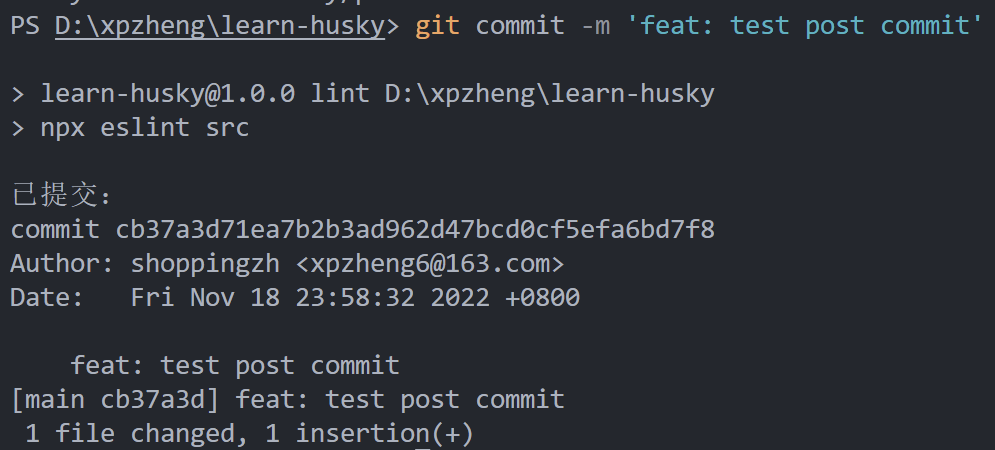
添加一个钩子
npx husky add .husky/post-commit 'echo "已提交:" & git log -1 HEAD'以上命令会创建一个post-commit(提交后)的钩子,并打印提交的日志:
提交前:代码美化与校验
接下来,我们将通过 husky 添加一个 pre-commit 钩子,在提交代码前,通过Prettier美化代码和ESLint检查代码。
npx husky add .husky/pre-commit然后,在 .husky/pre-commit 文件下编辑:
prettier --write src/**/*.{js,ts}
eslint src/**/*.{js,ts}这样,每次提交时,会进行代码的美化和校验,如果代码不符合规范,将会提交失败。
问题
这个方案乍看起来没什么问题,但是其实存在几个很明显的问题:
- 每次提交时,可能只提交了几个文件,但是都会对
src下的所有js/ts文件进行校验,实属没必要; - 不提交的代码不希望美化和校验,但是以上方案还是会继续美化和校验;
- 美化代码时会修改原代码,修改后的内容其实又回到了工作区,而不是在提交暂存区里。
使用lint-staged库解决问题
lint-staged 可以完美解决以上问题,它的原理是寻找暂存区内的文件,并且只对这些文件(你可以通过glob表达式继续过滤)进行美化和校验。
举例说,你只准备提交 src/1.js 文件,lint-staged 会将你的校验命令改造为:
eslint src/1.js下载lint-staged
pnpm i -D lint-staged
# yarn add -D lint-staged
# npm i -D lint-staged配置lint-staged
在 package.json 文件中添加配置:
"lint-staged": {
"*.{js,ts}": [
"prettier --write",
"eslint"
]
}需要注意的是,此处配置 prettier 和 eslint 命令并没有指定目标文件列表,lint-staged会帮我们在命令后拼接上文件列表,以达到只处理暂存区文件的目的。
注意这里的坑
第一次使用时,我在package.json中新增了一个脚本:
"script": {
"lint": "eslint src/**/*.{js,ts}"
}然后配置lint-staged为:
"lint-staged": {
"*.{js,ts}": [
"pnpm lint"
]
}注意!这样的做法是有大坑的,因为lint-staged的原理是改造你传入的命令,在其后拼接上文件列表,如果传入的命令是 pnpm lint ,那么拼接后的将会是 pnpm lint src/1.js,这个 src/1.js 是没法传递到eslint中的,所以eslint仍然会对 src 目录下的所有文件进行校验。
配置pre-commit钩子
接下来,你需要改造pre-commit钩子,从原来直接调用 prettier 或 eslint 的命令,变成调用lint-staged命令:
npx lint-staged到此处为止,提交前的git配置已全部完成,提交时,将只会美化和校验待提交的内容,已经提交的和暂不提交的内容,将不会处理。
提交中:日志规范
对提交日志进行规范有几个好处:
- 一致的提交日志方便查阅与定位问题;
- 好的日志规范可以方便未来生成清晰的版本日志。
提交日志的校验主要依赖于 commitlint 这个库,以下介绍它与 husky 配合使用的方法。
安装
pnpm i -D @commitlint/cli @commitlint/config-conventional
# yarn add -D @commitlint/cli @commitlint/config-conventional
# npm i -D @commitlint/cli @commitlint/config-conventional新增配置文件
在项目根目录下新增commitlint.config.js文件,这里我们继承一个常用的配置即可:
module.exports = {
extends: [
'@commitlint/config-conventional'
]
};与husky配合
因为husky可以轻松管理git钩子,我们可以为git仓库新增一个commit-msg的钩子,在该钩子里拿到用户的提交日志并校验,如果提交日志不符合规范,则抛出错误。
首先,我们使用husky新增一个commit-msg钩子:
npx husky add .husky/commit-msg 'npx --no -- commitlint --edit ${1}'然后,提交时就可以校验日志是否符合规范了:
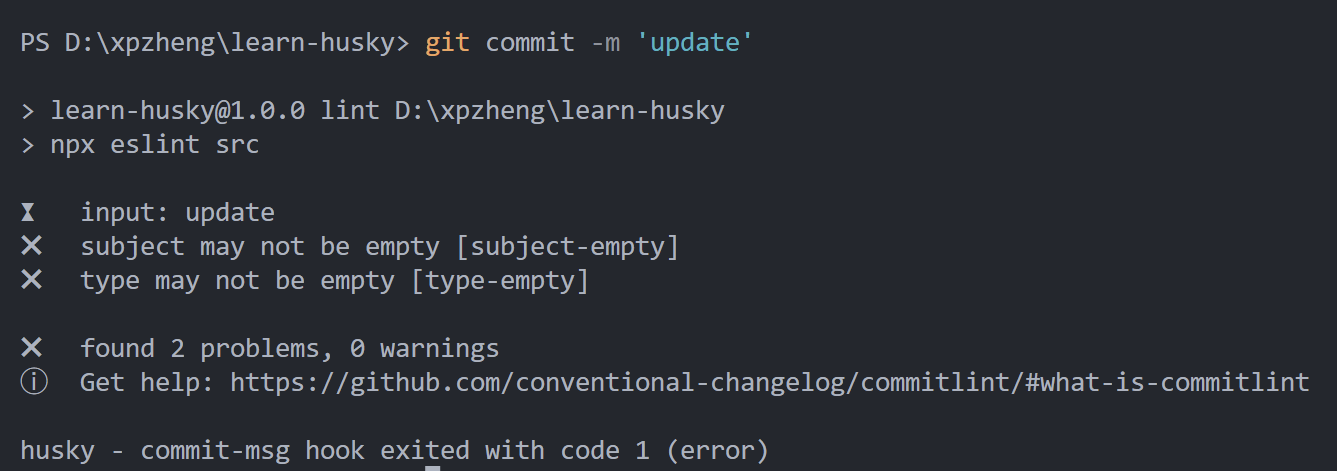
常见的git钩子

提交后:生成版本日志
通过对提交日志的校验,我们已经能够获得分类清晰且标准化的提交日志了。接下来需要将它们整理到版本的更新日志中,例如:
这种人为整理版本日志的方式最大的优点就是:灵活。但也带来了以下缺点:
- 一致性弱。因为过于灵活,所以多个版本日志可能存在不一致的情况;
- 工作量大,麻烦。每次版本更新,都要手动整理提交日志,过于麻烦。
TIP
因为版本日志其实只要客观反映本次版本更新的内容即可,完整、一致才是其追求的目标,因此,使用工具生成日志相比人工整理更为合理,也更加方便。
conventional-changelog-cli 是一个读取git提交日志并生成版本日志的库。下面介绍它的使用方法:
安装conventional-changelog-cli
pnpm i -D conventional-changelog-cli
# yarn add -D conventional-changelog-cli
# npm i -D conventional-changelog-cli在 package.json 中新增脚本
{
"scripts": {
"changelog": "conventional-changelog -p angular -i CHANGELOG.md -s"
},
}以后,你需要按照这样的工作流进行开发:
- 修改代码并提交
- 修改
package.json中的版本号 - 执行
npm run changelog生成日志 - 提交
CHANGELOG.md文件 - 推送提交
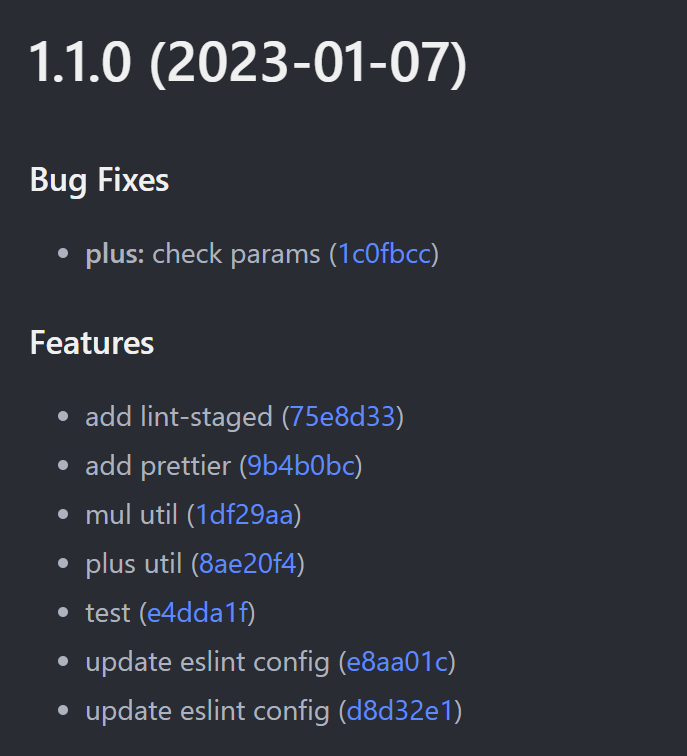
如上为自动生成的提交日志。
总结
整个过程中使用到了很多的第三方库(ESLint / Stylelint / Prettier / husky / commitlint / conventional-changelog-cli等),每个库各司其职、充分解耦,这样带来的好处是我们可以任意组合进行应用,也可以将过程中的某个库替换为其他的实现。
同时,我们也可以思考另一个方向:
因为整个工作流的搭建其实还是蛮复杂的,是否可以开发一个更上层的库,默认内置以上流程中的第三方库,可以做到开箱即用,而不需要每次都重新搭建?
不妨留下一个思考的新方向。
END.